-
Ce strategie de marketing să implementezi când îți lansezi o afacere
Wed, 05 Mar 2025 -
Cum să-ți crești afacerea în 2025: Ghidul complet pentru marketing, SEO, web design
Wed, 15 Jan 2025 -
10+ metode de promovare a unui site pe care merită să le încerci
Fri, 06 Dec 2024 -
Google va elimina suportul pentru Sitelinks Search Box
Tue, 22 Oct 2024 -
Noua politică de retenție a datelor Google Ads. Cum te poți pregăti
Tue, 15 Oct 2024
Google a actualizat recent documentația referitoare la fișierul robots.txt, clarificând aspecte importante legate de câmpurile acceptate și modul în care funcționează acest instrument esențial în gestionarea crawlerelor motoarelor de căutare.
În acest articol, vom explora noutățile, modul de funcționare a fișierului robots.txt, recomandările de utilizare și alte informații utile.
Ce este robots.txt?
Fișierul robots.txt este un fișier text simplu care se află la rădăcina unui site web (de exemplu, https://www.exemplu.com/robots.txt). Acesta este utilizat pentru a comunica instrucțiuni pentru crawlers (roboții) motoarelor de căutare, indicând ce pagini sau secțiuni ale site-ului ar trebui sau nu ar trebui să fie accesibile pentru indexare.
Cum funcționează robots.txt?
Când un crawler vizitează un site web, acesta caută fișierul robots.txt pentru a verifica dacă există reguli care îi restricționează accesul. Regulile sunt formulate prin directive care specifică user-agent-ul (crawlers specifici) și instrucțiunile asociate acestora.
Iată un exemplu de bază:
User-agent: *
Disallow: /privat/
Acest exemplu arată că toate crawlerele (reprezentate prin *) nu au permisiunea de a accesa orice pagină din directorul /privat/.
Noutăți din documentația Google
Google a clarificat, la începutul lunii octombrie, faptul că nu sunt acceptate câmpurile care nu sunt listate în documentația robots.txt. Asta înseamnă că orice directive care nu sunt explicit menționate în documentația oficială a Google vor fi ignorate. Este important pentru webmasteri, deoarece asigură o mai bună predictibilitate în comportamentul crawlerelor.
Structura și sintaxa robots.txt
Fișierul robots.txt respectă o sintaxă specifică, iar utilizarea corectă a acesteia este esențială pentru ca crawlerele să respecte instrucțiunile dorite.
Iată câteva directive comune utilizate în fișierele robots.txt:
➤ User-agent: Specifică crawlerul căruia i se aplică regulile. De exemplu, User-agent: Googlebot se referă la crawlerul Google.
➤ Disallow: Indică paginile sau directoarele care nu trebuie indexate.
➤ Allow: Permite accesul la pagini sau directoare specifice, chiar dacă un director mai mare este restricționat printr-o directivă Disallow.
Exemplu de fișier robots.txt:
User-agent: Googlebot
Disallow: /privat/
Allow: /public/
Ca Google să îți poată accesa conținutul, asigură-te că fișierul robots.txt permite ca entitățile user-agent „Googlebot”, „AdsBot-Google” și „Googlebot-image” să îți poată accesa site-ul cu crawlere.
În acest sens, poți adăuga următoarele rânduri la fișierul robots.txt:
| User-agent: Googlebot Disallow: User-agent: AdsBot-Google Disallow: User-agent: Googlebot-Image Disallow: |
Câmpurile autorizate în sintaxa Google pentru robots.txt
Pentru ca fișierul robots.txt să fie corect interpretat de Google și alte motoare de căutare, este important să respecți sintaxa corectă. Fiecare linie validă dintr-un fișier robots.txt este formată dintr-un câmp, urmat de două puncte și o valoare. Spațiile sunt opționale, dar recomandate pentru a îmbunătăți lizibilitatea. Orice comentariu poate fi inclus precedat de simbolul #, iar tot ce se află după acest simbol va fi ignorat.
Formatul general este: 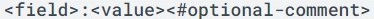
Google suportă următoarele câmpuri autorizate (alte câmpuri, cum ar fi crawl-delay, nu sunt acceptate):
1. user-agent: identifică crawlerul la care se aplică regulile.
De exemplu, User-agent: Googlebot se aplică pentru robotul Google. Această valoare nu este sensibilă la majuscule/minuscule.
2. allow: specifică calea URL care poate fi accesată de crawlere.
Aceasta este sensibilă la majuscule/minuscule și poate fi utilizată pentru a permite accesul la anumite fișiere sau directoare dintr-un director restricționat.
Exemplu de utilizare:
allow: /public/
3. disallow: specifică calea URL care nu trebuie accesată de crawlere.
Dacă nu este indicată o cale, regula va fi ignorată. De asemenea, valoarea este sensibilă la majuscule/minuscule.
Exemplu de utilizare:
disallow: /privat/
4. sitemap: specifică locația unui sitemap complet, printr-un URL absolut.
Aceasta poate fi utilizată pentru a furniza sitemap-uri motoarelor de căutare, precum Google și Bing, și nu este asociată cu niciun user-agent specific. URL-ul trebuie să fie complet calificat, incluzând protocolul și domeniul, și poate indica sitemap-uri care nu sunt găzduite pe același domeniu cu fișierul robots.txt.
Exemplu de utilizare:
sitemap: https://www.exemplu.com/sitemap.xml
Adăugarea corectă a acestor câmpuri în fișierul robots.txt asigură respectarea regulilor de către crawlere și reprezintă un ghid esențial de optimizare pentru gestionarea eficientă a accesului motoarelor de căutare, contribuind astfel la o mai bună indexare și performanță SEO a site-ului.
Recomandări pentru utilizarea robots.txt
- Planificarea structurii: Gândește-te bine la ce pagini vrei să restricționezi sau să permiți. Este important să eviți restricționarea accidentală a paginilor pe care dorești să le indexezi.
- Testarea fișierului: Utilizează instrumentele de testare disponibile în Google Search Console pentru a verifica dacă robots.txt funcționează conform așteptărilor. Acest lucru te poate ajuta să identifici problemele înainte ca acestea să afecteze indexarea.
- Revizuirea periodică: Actualizează periodic fișierul robots.txt pe măsură ce site-ul evoluează, asigurându-te că reflectă structura și politica curentă a site-ului.
- Evitați directivele neacceptate: Asigură-te că utilizezi doar câmpurile și directivele acceptate, conform documentației Google, pentru a evita confuziile și a asigura o funcționare corectă.
- Informarea echipei: Dacă lucrezi într-o echipă, asigură-te că toți membrii sunt conștienți de regulile din fișierul robots.txt, pentru a evita modificările neautorizate.
Fișierul robots.txt este un instrument important pentru gestionarea accesului crawlerelor la conținutul unui site web. Actualizările recente din documentația Google subliniază importanța utilizării corecte a acestuia și clarifică aspectele legate de câmpurile acceptate.
Prin urmare, webmasterii trebuie să fie atenți la structura și la directivele pe care le utilizează, pentru a se asigura că paginile dorite sunt indexate corect. Prin respectarea recomandărilor și actualizarea periodică a fișierului robots.txt, poți optimiza indexarea site-ului și poți îmbunătăți vizibilitatea acestuia în rezultatele căutărilor.
Sursa foto: pexels.com